
HTML معنایی چیست؟

HTML معنایی استفاده از نشانه گذاری HTML برای تقویت معنایی یا معنی اطلاعات در صفحات وب و برنامه های کاربردی وب به جای اینکه صرفاً برای تعریف ارائه یا ظاهر آن باشد. HTML معنایی توسط مرورگرهای وب سنتی و همچنین توسط بسیاری از عوامل کاربر دیگر پردازش می شود. CSS برای پیشنهاد ارائه آن
HTML معنایی استفاده از نشانه گذاری HTML برای تقویت معنایی یا معنی اطلاعات در صفحات وب و برنامه های کاربردی وب به جای اینکه صرفاً برای تعریف ارائه یا ظاهر آن باشد. HTML معنایی توسط مرورگرهای وب سنتی و همچنین توسط بسیاری از عوامل کاربر دیگر پردازش می شود. CSS برای پیشنهاد ارائه آن به کاربران انسانی استفاده می شود.
HTML از زمان پیدایش خود شامل نشانه گذاری معنایی بوده است. در یک سند HTML، نویسنده ممکن است، در میان چیزهای دیگر، “با یک عنوان شروع کند، عنوان و پاراگراف اضافه کند، بر متن تاکید کند، تصاویر اضافه کند، پیوندهایی به صفحات دیگر اضافه کند، [و] از انواع مختلف لیست ها استفاده کند.” .
نسخههای مختلف استاندارد HTML شامل نشانهگذاری نمایشی مانند <font> (افزوده شده در HTML 3.2؛ حذف در HTML 4.0 Strict)، <i> (همه نسخهها) و <center> (اضافه شده در HTML 3.2) هستند. همچنین عناصر span و div از نظر معنایی خنثی وجود دارد. از اواخر دهه 1990 زمانی که برگههای سبک آبشاری در اکثر مرورگرها شروع به کار کردند، نویسندگان وب تشویق شدند تا از استفاده از نشانهگذاری HTML ارائهای با هدف جداسازی محتوا و ارائه اجتناب کنند.
در سال 2001، تیم برنرز لی در بحثی در مورد وب معنایی شرکت کرد، جایی که ارائه شد که نرم افزارهای هوشمند ممکن است روزی به طور خودکار وب را بچرخانند و حقایق منتشر شده قبلی نامرتبط را به نفع کاربران نهایی پیدا، فیلتر و مرتبط کنند. . چنین عواملی حتی در حال حاضر نیز رایج نیستند، اما برخی از ایده های وب 2.0، ماشاپ ها و وب سایت های مقایسه قیمت ممکن است نزدیک شوند. تفاوت اصلی بین این ترکیبهای برنامههای کاربردی وب و عوامل معنایی برنرز لی در این واقعیت نهفته است که تجمیع و ترکیب اطلاعات فعلی معمولاً توسط توسعهدهندگان وب طراحی میشود که از قبل مکانهای وب و معنای API دادههای خاص مورد نظر خود را میدانند. له کردن، مقایسه کردن و ترکیب کردن.
یک نوع مهم از عامل وب که صفحات وب را به طور خودکار می خزند و می خواند، بدون اطلاع قبلی از آنچه ممکن است پیدا کند، خزنده وب یا عنکبوت موتور جستجو است. این عوامل نرم افزاری به وضوح معنایی صفحات وب که پیدا می کنند وابسته هستند زیرا از تکنیک ها و الگوریتم های مختلف برای خواندن و فهرست بندی میلیون ها صفحه وب در روز استفاده می کنند و امکانات جستجو را برای کاربران وب فراهم می کنند.
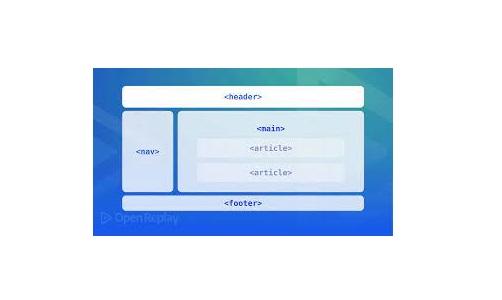
برای اینکه عنکبوتهای موتورهای جستجو بتوانند اهمیت تکههای متنی را که در اسناد HTML پیدا میکنند رتبهبندی کنند، همچنین برای کسانی که mashup و دیگر ترکیبها را ایجاد میکنند، و همچنین برای عوامل خودکارتر در حین توسعه، ساختارهای معنایی وجود در HTML باید به طور گسترده و یکنواخت اعمال شود تا معنای اطلاعات منتشر شده را نشان دهد.
در حالی که وب معنایی واقعی ممکن است به هستیشناسیها و فرادادههای پیچیده RDF بستگی داشته باشد، هر سند HTML با استفاده صحیح از سرفصلها، فهرستها، عناوین و سایر نشانهگذاریهای معنایی هرجا که ممکن است، سهم خود را در معنادار بودن وب میکند. این استفاده «ساده» از HTML «HTML ساده قدیمی معنایی» یا POSH نامیده شده است. استفاده صحیح از “برچسب گذاری” وب 2.0، سونومی هایی را ایجاد می کند که ممکن است برای بسیاری به همان اندازه یا حتی بیشتر معنی دار باشد. HTML 5 عناصر معنایی جدیدی مانند بخش، مقاله، پاورقی، پیشرفت، ناوبری، کنار، علامت گذاری و زمان را معرفی کرد. به طور کلی، هدف W3C این است که به آرامی راههای بیشتری را برای مرورگرها، توسعهدهندگان و خزندهها معرفی کند تا بهتر بین انواع مختلف دادهها تمایز قائل شوند و مزایایی مانند نمایش بهتر در مرورگرها در دستگاههای مختلف را فراهم کند.
عناصر نمایشی به طور رسمی در توصیههای HTML 4.01 و XHTML منسوخ نشدهاند، اما در مقابل توصیه شدهاند. در HTML 5، برخی از آن عناصر، مانند i و b، هنوز مشخص شده اند، زیرا معنای آنها به وضوح تعریف شده است “به گونه ای که از نظر سبکی از نثر معمولی خارج شود بدون اینکه هیچ اهمیت اضافی را منتقل کند”.
در مواردی که یک سند به معنایی دقیق تری نسبت به آنچه در HTML بیان شده است نیاز دارد، بخش هایی از سند ممکن است در عناصر span یا div با نام های کلاس معنی دار مانند <span class=”author”> و <div class=”invoice” محصور شوند. > در جایی که این نام کلاس ها نیز یک شناسه قطعه در یک طرحواره یا هستی شناسی هستند، ممکن است به معنای تعریف شده تری پیوند بخورند. میکروفرمت ها این رویکرد به معناشناسی را در HTML رسمی می کنند.
یکی از محدودیتهای مهم این رویکرد این است که چنین نشانهگذاری مبتنی بر گنجاندن عنصر باید شرایط شکلگیری خوب را برآورده کند. از آنجایی که این اسناد به طور گسترده دارای ساختار درختی هستند، این بدان معنی است که تنها قطعات متعادل از یک درخت فرعی را می توان به این روش علامت گذاری کرد. ابزاری برای علامتگذاری هر بخش دلخواه HTML به مکانیزمی مستقل از ساختار نشانهگذاری نیاز دارد، مانند XPointer.
HTML معنایی خوب همچنین دسترسی به اسناد وب را بهبود می بخشد (همچنین به دستورالعمل های دسترسی به محتوای وب مراجعه کنید). زمان با خواندن اطلاعات مکرر یا نامربوط زمانی که به درستی علامت گذاری شده است.

در سال 2010، گوگل سه شکل از ابرداده های ساختاریافته را مشخص کرد که سیستم های آنها برای یافتن محتوای معنایی ساخت یافته در صفحات وب استفاده می کنند. چنین اطلاعاتی، زمانی که مربوط به نظرات، نمایههای افراد، فهرستهای کسبوکار و رویدادها باشد، توسط Google برای بهبود «قطعه» یا قطعه کوتاهی از متن نقلقولشده که وقتی صفحه در فهرستهای جستجو نشان داده میشود، استفاده میشود. Google مشخص میکند که این دادهها ممکن است با استفاده از میکروداده، میکروفرمتها یا RDFa داده شوند. Microdata در داخل آیتم نوع و ویژگی های itemprop اضافه شده به عناصر موجود HTML مشخص می شود. همانطور که در بالا توضیح داده شد، کلمات کلیدی میکروفرمت داخل ویژگی های کلاس اضافه می شوند. و RDFa متکی بر rel، typeof و ویژگی های ویژگی است که به عناصر موجود اضافه شده است.
برچسب ها :
ناموجود- نظرات ارسال شده توسط شما، پس از تایید توسط مدیران سایت منتشر خواهد شد.
- نظراتی که حاوی تهمت یا افترا باشد منتشر نخواهد شد.
- نظراتی که به غیر از زبان فارسی یا غیر مرتبط با خبر باشد منتشر نخواهد شد.
ارسال نظر شما
مجموع نظرات : 0 در انتظار بررسی : 0 انتشار یافته : 0